In my last post, I introduced a new project of mine: Bud
(BudLang). It's goal was simple: explore how fast a
#![forbid(unsafe_code)] language written in Rust could be. Earlier this week,
I was working on it again and thought about how I wanted loops to work.
One problem with having no unsafe code is dealing with the lifetimes of the
Value types in the virtual machine. I cannot store borrowed data in the virtual
machine, because it would introduce lifetime requirements, and the only way to
iterate over Rust's built-in HashMap requires borrowing data. The
only way I could think to create iterators for the Map type in Bud would be to
collect the HashMap's keys into a Vec. But this requires an extra allocation
and data cloning.
I realized what I wanted was a little different: an indexable hash map. Rust has
a sorted map using BTreeMap, but that has completely different
performance and usage implications when compared against a hash map.
I searched and found a popular crate indexmap that would solve my
need perfectly. I couldn't bring myself to use it, however, as one of the things
I loved about the budlang crate is that it has no dependencies. Additionally,
since the primary goal of Bud was to not use any unsafe, bringing in indexmap
feels against the spirit of what I wanted to accomplish with Bud.
So, I set out to see how fast an indexable hash map implementation that uses no
unsafe could be.
But you are still using
unsafebecausestduses it! Why avoid a single, well-trusted dependency if it usesunsafe?
This is a valid question. When I adopted Rust in 2019, one of the reasons I felt
it was well designed was the concept of unsafe. Anyone who has built complex
systems knows the benefits of writing a solid foundation and abstracting atop
that solid foundation. That's exactly what unsafe allows: encapsulating code
where you take over for Rust's safety guarantees. This design decision enables
end users of most Rust libraries to often not ever need to use unsafe. Yet, as
a Rust user, I know the power is there if I ever need it.
Despite loving the language feature, I see it as a double-edged sword. As I was
learning Rust, I saw many newer Rustaceans reach for unsafe in basic
situations. For example, using Slice::get_unchecked instead of Slice::get to
avoid the extra bounds check. In some cases, it might be a good optimization.
But most of the time I've personally profiled and optimized code, I found that
performance rarely changed.
How can removing extra checks not yield faster code? Optimizers are scary good
these days, and they keep getting better. In many cases, the extra bounds checks
are already being optimized away by the compiler. It's beacuse of the power of
optimizers that I hope that most Rust users never need to reach for unsafe
when optimizing their own code.
To put that hope to the test: Can a completely safe implementation of an
indexable hash map compete on performance with indexmap, which is
powered by hashbrown?
Surprisingly, the answer is: yes!
How does an indexable hash map work?
In a typical indexable hash map, the entries are stored in a list separate from a hash map which allows retrieiving the index of the entry from a given key. A naive approach would look something like this:
pub struct IndexMap<Key, Value> {
entries: Vec<(Key, Value)>
by_key: HashMap<Key, usize>,
}
This approach has one glaring downside: it requires storing each Key twice:
once in the entries list and once in the HashMap. This may not sound like a
huge deal, but consider the effect when using a String as a key: a separate
copy of each heap-allocated String would be needed. Since this would yield
extremely bad performance, I decided to write my own hash map from the ground
up.
Hash maps are relatively simple data structures to understand. At their core is a list of "bins". When attempting to insert a key/value pair or find a key, the key is hashed to producing an integer value. The integer is converted to an index into the list of bins (traditionally using modulus or bit masking).
The complexity arises when two entries end up needing the same bin. These collisions can happen for two reasons, even with distinct keys: 1) two distinct values can produce the same hash, and 2) the two distinct hashes can convert to the same bin index.
How does BudMap work?
I went through many design iterations, and here is my current set of data structures:
pub struct BudMap<Key, Value, HashBuilder = RandomState> {
/// A dense list of all entries in this map. This is where the actual
/// key/value data is stored.
entries: Vec<RawEntry<Key, Value>>,
/// A list of bins that is at least as big as the bin count
/// (`bin_mask.into_count() + 1`). All entries beyond the bin count are
/// colliding entries.
bins: Vec<Bin>,
/// A bit mask that can be applied to a hash to produce an index into
/// `bins`. This means all valid bin counts are powers of 2.
bin_mask: BinMask,
/// The index inside of `bins` of the last collision that was freed. This is
/// the start of a singly-linked list that points to all currently free
/// collision bins.
free_collision_head: OptionalIndex,
/// The [`BuildHasher`] implementor via which keys are hashed.
hash_builder: HashBuilder,
}
/// A single key/value entry in a [`BudMap`].
struct RawEntry<Key, Value> {
/// The computed hash of `key`.
hash: u64,
/// The entry's key.
key: Key,
/// The entry's value.
value: Value,
}
/// A hash-map bin.
struct Bin {
/// The index inside of the [`BudMap::entries`] vec, if present.
entry_index: OptionalIndex,
/// If present, an index inside of [`BudMap::entries`] for the next bin that
/// collides with this bin. This forms a singly-linked list of bins.
collision_index: OptionalIndex,
}
/// A wrapper for a `usize` which reserves `usize::MAX` as a marker indicating
/// None. `std::mem::size_of::<Option<usize>>()` is 2x usize, while
/// `size_of::<OptionalIndex>()` remains 1x usize.
struct OptionalIndex(usize);
/// A bitmask for a 2^n quantity of bins.
struct BinMask(usize);
In this design, I avoid the Key duplication problem by building my own hash
map where Bin::entry_index is used to find the entry as needed.
Collisions cause extra bins to be appended to the end of the bins list. By using
the same storage buffer, we prevent a significant number of extra allocations
other collision strategies ended up requiring. The bin_mask identifies how
many entries in the Vec<Bin> are used as normal bins.
Because the entries are simply stored in a Vec, guaranteeing iteration order
or allowing accessing entries by index is efficient and simple. To perform a
lookup by key, the key is hashed and then masked using bin_mask. The bin is
loaded at that calculated index. If the key of the associated RawEntry for
that Bin is the one being searched for, the RawEntry's value can be
returned. If it isn't the correct key, the bin at Bin::collision_index is
checked. The process is repeated until either the correct key is found or
Bin::collision_index is None.
How does BudMap perform?
There are countless ways to measure hash map performance. I wanted to look at three common cases: retrieving a value out of a map of a given size, filling an empty map with x entries, and removing and then reinserting a record in a map of a given size. These measurements should give a decent indicator of overall performance.
These benchmarks all are tested with link time optimization
enabled and use the fnv crate to provide consistent hashing across
benchmark runs for hashing with all map types. A seeded random number generator
is used to generate random u32 keys and u32 values.
Even though HashMap isn't a viable option for my use case, I included it as a
reference point.
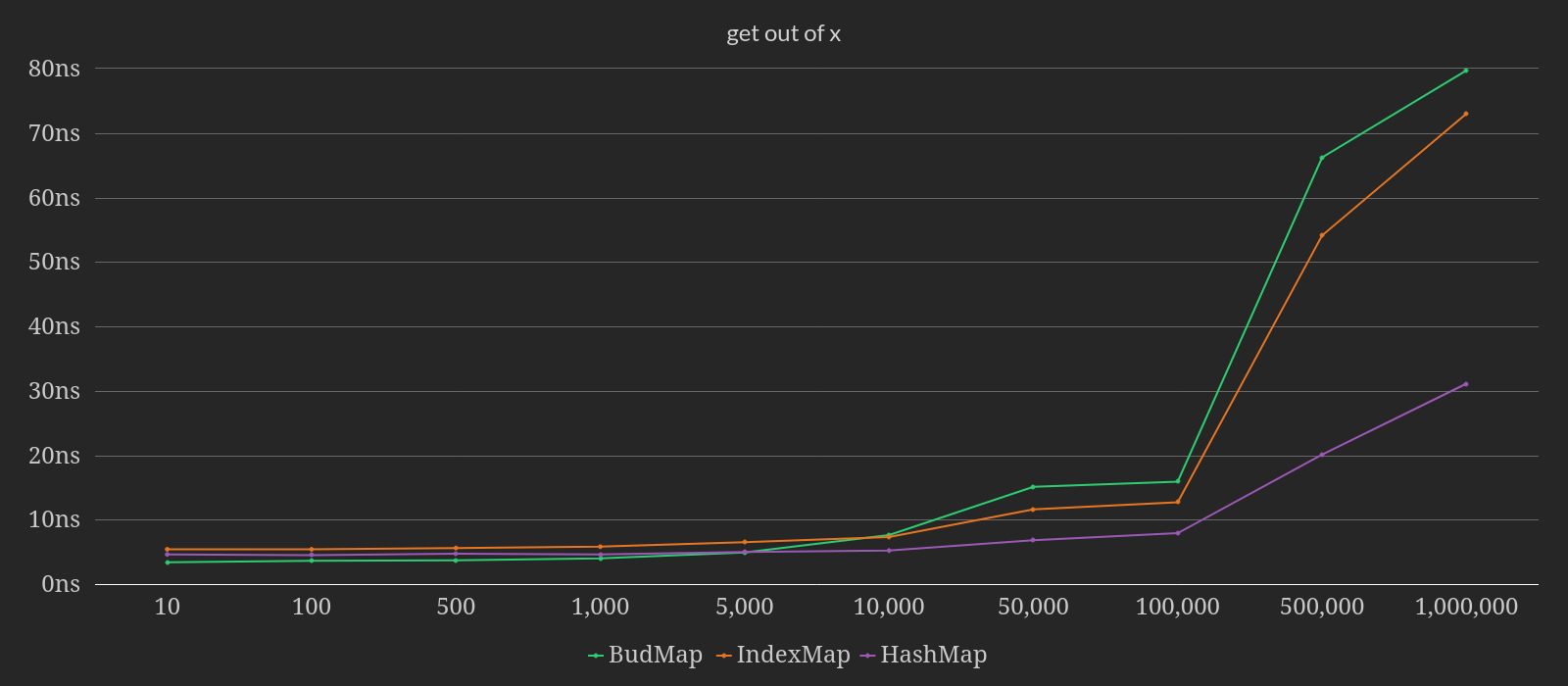
The above benchmark tests retrieving any entry by key at various map sizes. BudMap
actually outperforms IndexMap until the map size reaches 5,000 keys. As the
map continues to get more keys, the performance scales roughly in-line with
IndexMap, although IndexMap is a clear winner with the larger maps.
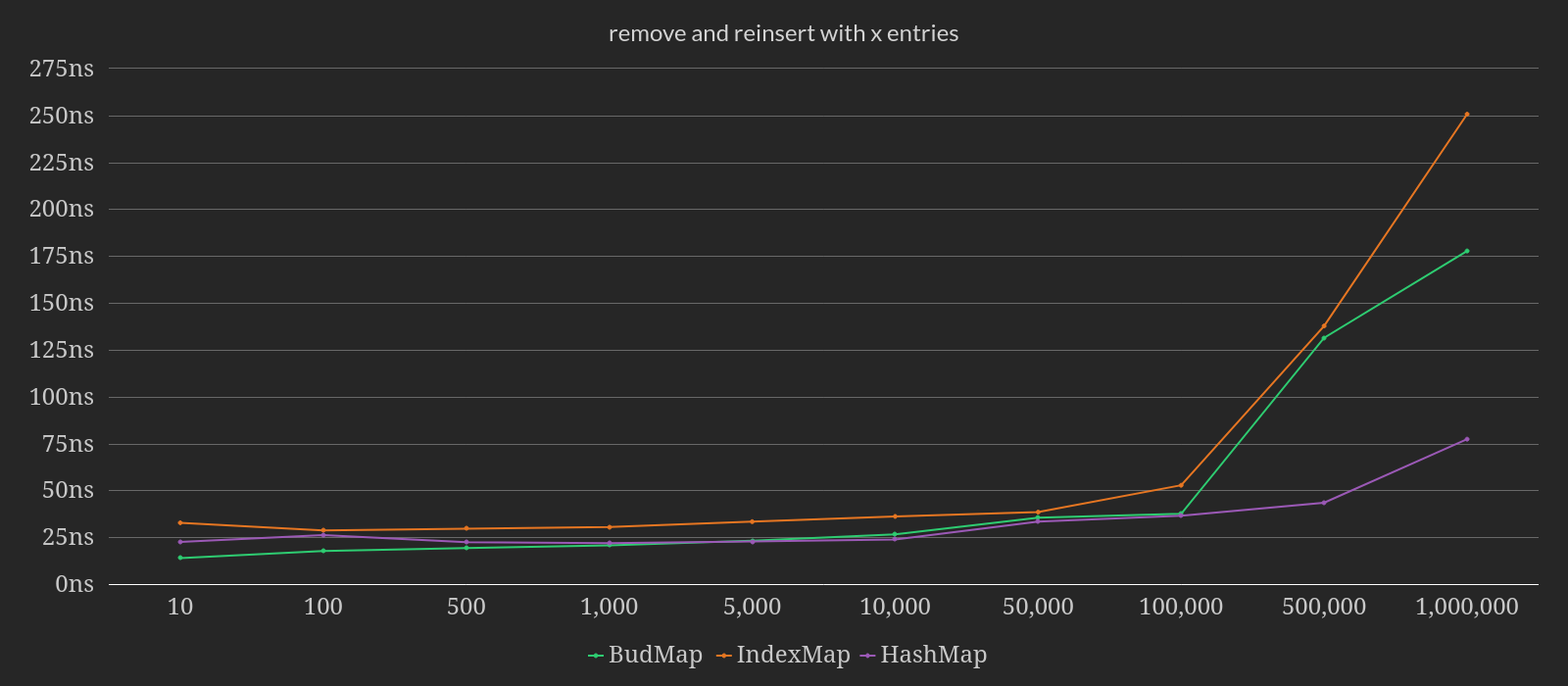
The second benchmark removes an entry by key and then reinserts it into maps of
various sizes. BudMap outperforms IndexMap across the board.
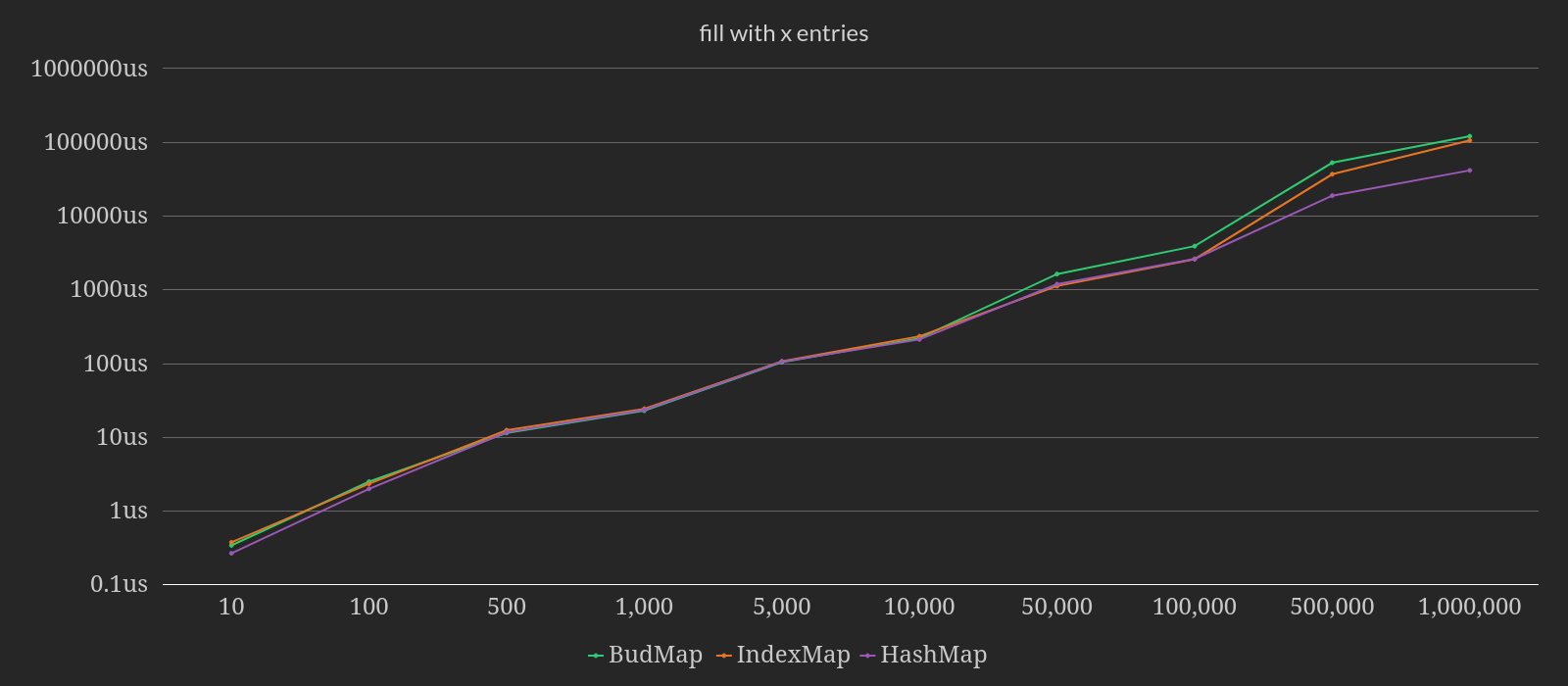
This final benchmark is designed to test how fast "rebinning" happens. It starts with an empty map with default capacity and inserts X number of rows. The time reported is the time of inserting all records. Because the time goes up for each measurement, I opted to display this graph in logarithmic scale. Without this decision, it would be impossible to view this graph and glean any useful information out of the smaller measurements.
In this benchmark, BudMap stays neck and neck with IndexMap until the 50,000
entry benchmark. After that, BudMap becomes slower than IndexMap -- up to
50.3% slower.
To attempt to summarize my general findings, BudMap appears to be as fast or
faster than IndexMap on maps with fewer than 10,000 keys while IndexMap
generally outperforms BudMap with larger maps. Given my anticipated use cases
of Bud, this meets my goals.
Another observation is complexity. BudMap is implemented in a single
file containing just 638 lines of code (LOC). It also has an additional
256 LOC of tests in another file, which to be honest is not enough. IndexMap
contains over 5k LOC and depends on hashbrown which has another
10k LOC. BudMap doesn't implement a Set type (yet?) and is missing many APIs
that the other crates have. For many users of Bud, my choice to roll my own
rather than bring in an extra dependency will yield better compile times.
My implementation is able to remain so simple because Vec provides the heavy
lifting for me. This is what I love about Rust -- I was able to create a
completely memory safe indexed hash map using only Rust's standard library and
no unsafe code that does a reasonable job of competing against an
unsafe-weilding alternative.
My takeaways
There are some problems in which unsafe is unavoidable. Outside of that, I
prefer to find approaches that don't require unsafe. In general, I find that I
can create code that performs similarly to the unsafe code, and I don't have
the mental overhead of verifying all of my unsafe operations don't introduce
undefined behavior.
However, this experiment also shows that as the maps get to larger sizes, the
unsafe-utilizing libraries are able to end up with better performance.
I find that the most impactful optimizations are usually aglorithmic in nature. It's rare to find that removing a single bounds check will drastically increase performance of the measured code. You're more likely to find significant performance gains by changing the approach to the problem rather than doing micro-optimizations.
If one of Bud's primary goals wasn't to avoid unsafe, I would have used
indexmap in a heartbeat. It's wonderful being able to use a highly
optimized library that has been battle-hardened and reviewed by many sets of
eyes. Because it is a great, well-maintained crate, I consider Bud unique in its
"need" of an alternate crate and don't currently plan on releasing BudMap
separately from Bud.
How goes BonsaiDb's storage rewrite?
As some people who will be reading this are primarily interested in my main project, BonsaiDb, I wanted to provide a brief update on that front. I uploaded a rewrite of my new write-ahead log two weeks ago. Since then, I have been reworking Sediment to use it.
I ended up starting fresh on that attempt earlier this week because I decided my first approach wasn't ideal. It was during that context switch that I decided to tackle something quick on Bud... "quick" -- you can guess what I spent the rest of the week working on!
Despite getting distracted by this project, I'm excited to finish hooking up the WAL to Sediment and getting new benchmark results. Even after I finish this phase, there will still be one more significant chunk of work to allow Nebari to reap the rewards of the WAL. My current goal is to have the new storage layer hooked up to BonsaiDb by the end of the year.