Prelude: Why I didn't want to use serde-json
Last week, I was looking into exploring ActivityPub, the protocol that powers Mastodon and the Fediverse. It uses a standard format for its JSON payloads: JSON-LD Compacted Document Form. A simple ActivityPub activity could look like this:
{
"@context": "https://www.w3.org/ns/activitystreams",
"type": "Note",
"to": ["https://chatty.example/ben/"],
"attributedTo": "https://social.example/alyssa/",
"content": "Say, did you finish reading that book I lent you?"
}
The @context field is very important -- it controls how the rest of the
document is interpretted. One of the neat things that you can do is extend the
document's schema:
{
"@context": {
"@vocab": "https://www.w3.org/ns/activitystreams",
"ext": "https://canine-extension.example/terms/",
"@language": "en"
},
"summary": "A note",
"type": "Note",
"content": "My dog has fleas.",
"ext:nose": 0,
"ext:smell": "terrible"
}
To understand what each field name means, the @context must be referenced. In
this example, ext:nose is actually a nose defined in the ext vocabulary
located at https://canine-extension.example/terms/. However, the usage of
ext is completely arbitrary: it can be anything.
As far as I'm aware, there is no good way to deal with this flexibility in parsing from Serde. There are some existing ActivityPub/JSON-LD related crates, but without going into specific reasons, I wanted to take a stab at my own implementation.
I knew from experience that serde_json::Value can't store borrowed data. For
my use case, I wanted to find a crate that allowed me to borrow data from the
JSON I was parsing, rather than needing a lot of tiny allocations for each
string. Since every object key in JSON is a string, they add up quickly.
Discovering Crates is Hard
I spent some time looking on both lib.rs and crates.io for a crate that matched my desires. There are a lot of JSON parsers out there. And, a significant number of them also do not allow borrowing their data from the input.
Since I have previously written JSON parsers for other languages and I knew JSON wasn't too complicated, I decided I would just write my own.
While working on my own implementation, a thread popped up on Reddit where I discovered several valuable resources:
- Serde's
json-benchmark, which compared the crates:serde-jsonjsonsimd-jsonrustc-serialize(deprecated/archived)
- A recommendation for
json-deserializer - Comments recommending either
simd-jsonorjson
With these new resources, I felt silly for wasting my time on my own
implementation. I relaxed for the rest of the evening, and decided to adopt the
json crate in the morning.
All is not OK in the Rust JSON ecosystem
Before using the json crate, I wanted to look into it a little more.
The last release was March 18, 2020. This isn't necessarily worrysome, as JSON
is a very limited format. It should be possible for JSON crates to reach
stability and not need additional changes. If that was the case, though, why not
release a 1.0 at some point in the last 3 years? Additionally, why is there no
README on the crates.io listing?
I decided to see if anyone asked either question in the Github issues. Instead, I saw users asking if the project was abandoned. Additionally, I saw what appears to be a legitimate undefined behavior issue that was reported on February 1, 2021 and was never commented on or addressed. I've verified that code is still triggering an error in Miri.
Given that I was just reading people recommending the project, I felt like the word needed to be spread about this particular crate. It has a lot of daily downloads. I filed a security advisory (sorry for all the broken audits!) and an issue that led to removing the crate from the json-benchmark project.
So what about json-deserializer, which another commentor
was suggesting in a fairly-well-upvoted comment? Since I was testing my own
library against the json.org JSON Checker's suite, I decided I
would modify that suite quickly to test json-deserializer. Unfortunately, this
led to another issue being filed.
In the face of these experiences this morning, I decided to keep pursuing my crate.
Introducing my take on parsing JSON: JustJson
I'm pursuing a different idea than I think hasn't been fully explored in Rust (although, given how many JSON crates exist, maybe it has). I think it has some merits, which is why I have been working on this idea at all. The basic premise is that I want to parse a JSON value with as few allocations as possible. Obviously, objects and arrays will always require allocations -- there needs to be storage for the object's key/value pairs or the array values. What if you could lazy-decode strings and floats?
You might be asking yourself, "why isn't that possible today?" The short answer:
escapes. Consider the JSON string: "\n". To convert this to a Rust string, the
2 bytes representing the escaped \n character must be converted to its
ASCII/UTF-8 representation. From what I've found, every existing Rust crate that
parses the JSON DOM will decode the escapes at the time of parsing. This means
that whenever escape sequences are encountered, a new String must be allocated
to store the decoded version.
My idea is to avoid that extra allocation. In JustJson, the Value type has a
generic parameter. When parsing JSON, the returned type is Value<&str>.
Numbers and strings are validated to properly detect any structural issues or
invalid unicode, but the JsonStrings and JsonNumbers store a reference to
their original source as well as some metadata gathered during the parse
operation.
This allows JsonString to implement PartialCmp<&str> such that:
- If no escapes are present, the underlying
&strcan be directly compared against Rust strings using the built in comparison implementation. - If escapes are present, the decoded length can be checked against the
&strlength to avoid any string data comparison. - If escapes are present, they are decoded on the fly as part of the string comparison operation.
The only question is, does this delay of processing help or hurt? As with many things, my guess is that it depends on the use case.
Initial benchmark results
Let me preface this section by saying that benchmarking JSON parsing is a challenging problem. JSON payloads vary greatly. Initially, I only tested my library against a very basic, small JSON payload in both compact and pretty-printed forms:
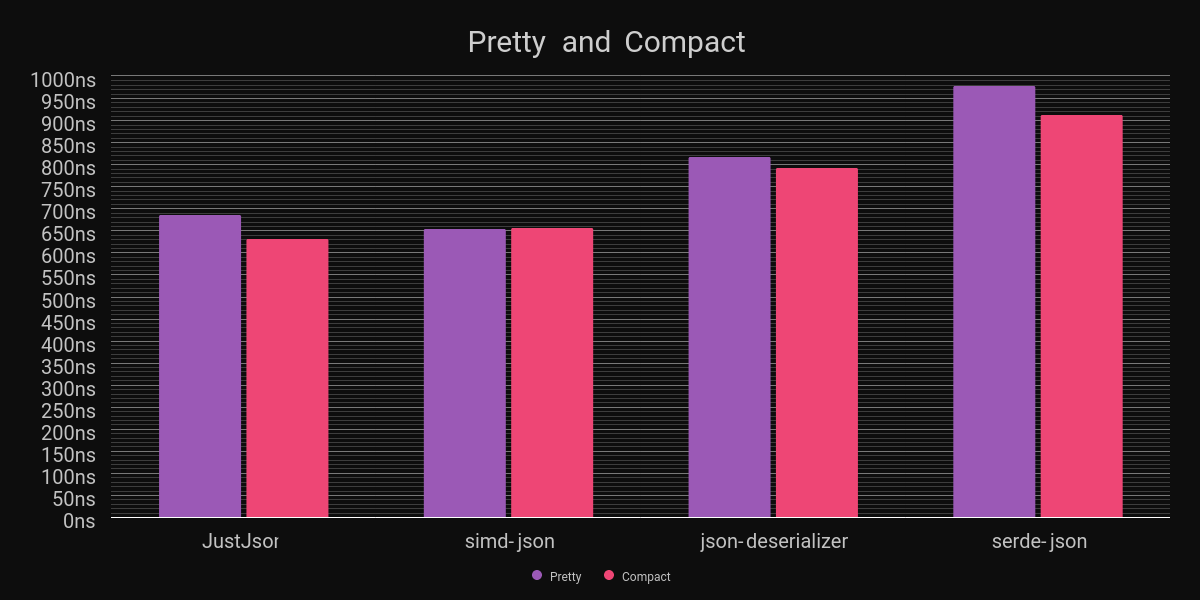
I'm very proud of these results, given that I've only spent a few days on this
project. However, what about that json-benchmark? I added
both json-deserializer and JustJson to the
fray, and here's the raw output of the DOM benchmarks:
DOM
======== justjson ======== parse|stringify =
data/canada.json 370 MB/s 2010 MB/s
data/citm_catalog.json 670 MB/s 1530 MB/s
data/twitter.json 530 MB/s 3270 MB/s
=== json-deserializer ==== parse|stringify =
data/canada.json 490 MB/s
data/citm_catalog.json 550 MB/s
data/twitter.json 300 MB/s
======= serde_json ======= parse|stringify =
data/canada.json 330 MB/s 520 MB/s
data/citm_catalog.json 560 MB/s 800 MB/s
data/twitter.json 410 MB/s 1110 MB/s
==== rustc_serialize ===== parse|stringify =
data/canada.json 190 MB/s 87 MB/s
data/citm_catalog.json 300 MB/s 230 MB/s
data/twitter.json 160 MB/s 350 MB/s
======= simd-json ======== parse|stringify =
data/canada.json 450 MB/s 560 MB/s
data/citm_catalog.json 1380 MB/s 1060 MB/s
data/twitter.json 1260 MB/s 1560 MB/s
These benchmarks use larger payloads. canada.json is composed of a lot of GPS coordinates stored as arrays of arrays. citm_catalog.json has a fairly general purpose data set with a good blend of data types. And finally, twitter.json contains the largest amount of string data.
When looking at my impressive results for stringify, remember that JustJson is
essentially cheating at this benchmark: because the JSON strings and numbers are
left in their original form, converting a Value to JSON is basically a series
of memcpys.
simd-json is truly impressive. If you can afford to compile your
binaries with target_cpu=native, it is crazy fast. For my particular
ActivityPub idea, if I ever ship it, the goal would be to allow other users to
download pre-built binaries, which means I would not want to build with
target_cpu=native to maximize binary compatibility. How does simd-json
perform without target_cpu=native? Here's the same benchmark as before, but
without the SIMD support enabled:
======= simd-json ======== parse|stringify ===== parse|stringify ====
data/canada.json 310 MB/s 560 MB/s
data/citm_catalog.json 890 MB/s 1060 MB/s
data/twitter.json 760 MB/s 1390 MB/s
Well, that was faster than I was anticipating! While I am able to parse
canada.json faster, the other files show simd-json as a clear winner.
One more idea
What you may not realize is that you've witnessed a moment where I was happily writing a blog post assuming something I had read was true. Then, when I went to test that assumption, the results were completely different than expected. You know what happens when you assume?
I decided to take a closer look at the simd-json project. It
looks quite well maintained, and while there is an open issue regarding
soundness, I am quite hopeful that any such issues will be addressed
over time. While browsing various issue threads and some pull requests, I found
mentions of how they use a "tape" structure while parsing that was then gathered
back up into the output Value type.
This led me to have one more idea on how to implement the laziest JSON parser
with as few allocations as possible: store the entire tree in a single Vec and
index into it. And, today I implemented it.
How does it stack up? Here's the output of json-benchmark:
| Library | canada.json | citm_catalog.json | twitter.json |
|---|---|---|---|
| Value | 370 MB/s | 670 MB/s | 530 MB/s |
| Document | 460 MB/s | 800 MB/s | 590 MB/s |
| simd-json w/o SIMD | 310 MB/s | 890 MB/s | 760 MB/s |
| simd-json | 450 MB/s | 1380 MB/s | 1260 MB/s |
This new strategy extended my lead on the canada.json file, but wasn't able to
close the gap on the other two files. While it's only been a few days of working
on this library, I have spent enough time on this distraction, and I am ready to
get back to work on the project I was originally working on.
Why I'm continuing development of JustJson
For almost all JSON parsing use cases, I would highly recommend using
serde-json. It's stable, reliable, and the convenience of Serde
is hard to beat. Additionally, it can even borrow some string data when not
parsing to its Value type. There's very little reason to consider anything
beyond serde-json.
Given how amazing the simd-json crate appears, if you need a borrowed JSON DOM parser or want a faster Serde-compatible JSON parser, I generally would recommend it for people who do not mind having dependencies with a lot of unsafe code.
I personally have a view that unsafe code should be minimized when possible.
JustJson uses unsafe, but only for one purpose: skipping a second UTF-8
validation pass on already validated data, which is serde-json and many others
also do. There are currently 3 expressions wrapped in unsafe blocks in JustJson.
Beyond the limited usage of unsafe, I've focused on rigorous testing with this crate. The only remaining task I want to do is set up a fuzzer, but I am hopeful fuzzing will not unveil any issues.
Lastly, I think the idea of a very-lazy JSON parser is interesting, and it's been fun to explore so far. It fits my use case like a glove, since I wrote it with my problem in mind.
It's for all of these reasons that I am going to continue development of JustJson while still highly recommending other libraries to most Rust developers.